Strava-data en space syntax
[longread, circa 20 minuten]
Dit wetenschappelijke onderzoeksartikel schreef ik in 2019. Doel was aan te tonen dat space syntax-modellen van steden en/of regio’s een goed beeld geven van daadwerkelijk fietsgedrag in Nederland. We beschikten over drie datasets: Eén jaar data van Strava en één week data van de Fietstelweek en twee weken tellen door de gemeente Dordrecht op een beperkt aantal telpunten. Allebei in de Drechtsteden, gedurende 2016.
Balász Dukai was verantwoordelijk voor het opschonen en visualiseren van de Strava- en Fietstelweek-data en de koppeling aan het Space Syntax-model. Richard van de Werken van bureau Hastig dacht mee.
Ik presenteerde de bevindingen op het jaarlijkse congres van de Royal Geographic Society in Londen in augustus 2019.
ABSTRACT
Big data is al jaren een modewoord. Non-stop worden enorme hoeveelheden data geproduceerd. Door bedrijven, door instellingen en vooral door burgers zelf. Met hun smartphones leggen ze hun bewegingen, locaties en interacties vast. Self-tracking-apps zoals Strava tonen prachtige visualisaties van deze gegevens op hun websites. Het binnen stedelijk ontwerp zinvol gebruiken van zulke gegevens stuit echter nog steeds op grote hindernissen.
Ten eerste worden de meeste gegevens weliswaar door de gemeenschap – u en ik – geproduceerd, maar zijn commerciële bedrijven eigenaar. Dat leidt tot problemen. Ten eerste worden gegevensverzoeken vaak niet soepel afgehandeld en, ook na uiteindelijk verkregen toestemming, blijft de toegang tot gegevens beperkt. De tweede kwestie is de betrouwbaarheid, transparantie en relevantie. Datasets bevatten om te beginnen gebruikersbias, zijn onderhevig aan ‘slijtage’ en worden op weinig transparante wijze nabewerkt, voordat ze in de handen van de onderzoeker terechtkomen. En ten derde: Besluitvormers vertrouwen blind op data en zien de valkuilen niet.
Met de regio Drechtsteden als voorbeeld laten we zien hoe self-tracking data wél effectief valt te gebruiken. We analyseren een Strava-dataset van meer dan 100.000 ritten met een herkomst en/of bestemming binnen de Drechtsteden, en een kleinere Fietstelweek-dataset. We laten zien dat Strava-en Fietstelweek-gegevens inderdaad bruikbaar zijn om gedetailleerde dagelijkse bewegingspatronen weer te geven, maar binnen bepaalde beperkingen. We laten ook zien hoe Space Syntax cruciaal is bij het combineren van datasets en het trekken van de juiste conclusies. Juist de combinatie van big data en een netwerkmodel biedt een onmisbare basis voor het bijsturen van onze hedendaagse steden.
Keywords
Self-tracking, crowd-sourced informatie, fietsstromen, Strava, Fietstelweek, Space Syntax
INLEIDING
In West-Europese steden is de fiets [opnieuw] sterk in opmars. Burgers investeren in de voertuigen en lokale overheden in de infrastructuur die fietsen als vervoerswijze levensvatbaar maakt. De fiets is bovendien een manier om een gezonde levensstijl, duurzame stedelijke omgevingen en economisch concurrerende steden te verbeteren. Instellingen zoals de Deense en Nederlandse Fietsambassades promoten dit evangelie over de hele wereld. Een groot deel van dit publieke media-offensief is gericht op projecten en initiatieven die commerciële waarde combineren met maatschappelijke doelen. Zowel top-down als bottom-up.
Op wetenschappelijk vlak komt dit tot uiting in een groeiend aantal studies die zich richten op fietsstromen. Vooral routekeuze is een intensief bestudeerd fenomeen. Deze onderzoeken laten in de loop der jaren een geleidelijke verschuiving zien van het gebruik van enquêtes en vragenlijsten [Westerdijk 1990, Stinson 2003, Cherry 2006, Sener 2009, Yang 2013, Song 2016] naar het gebruik van GPS en tracking apps. Werken met GPS-gegevens is de norm geworden.
Veel artikelen baseren hun conclusies echter op zeer kleine datasets. Methodologieën omvatten het tellen van fietsers bij een beperkt aantal poorten [Penn 1994, Criollo-Precciado 2012, Law 2013] of het volgen van een kleine groep individuele fietsers met behulp van speciale GPS-trackers [Broach 2010, Halldorsdottir 2013, Casello 2014, Pereira Segilhada 2014, Allemann 2015, Montini 2015] of zelf ontwikkelde mobiele apps [Zimmermann 2016, Manum 2017]. Nu steeds meer big data verzameld wordt, is dit geen bevredigende manier van werken meer.
Big datasets over fietsgedrag bestaan. Fietsers gebruiken al jaren apps om hun bewegingen, locaties, reisdoelen en interacties zelf te volgen. Zo beschikken bedrijven als Strava, MapMyRide, Suunto en vele andere over grote crowd-sourced datasets, door burgers zelf geproduceerd. Hun websites tonen prachtige visualisaties. Strava heeft wereldwijd momenteel [2021] meer dan 75 miljoen geregistreerde leden. Het gebruik van hun verzamelde gegevens voor wetenschappelijk onderzoek of beter gemeentelijk beleid kan een echte zegen zijn [Norman 2015].
Dit stuit echter nog op grote hindernissen. Ook al is de data feitelijk door burgers zelf verzameld, zijn bedrijven eigenaar. Het gebruik van hun gegevens brengt praktische problemen met zich mee, zoals financiële vergoedingen, beperkende gebruikerslicenties en ondoorzichtige gegevensverwerking. Een ander fundamenteel probleem is de bias die veel van deze datasets hebben. Elke app richt zich op een specifieke doelgroep en [meestal sportief of recreatief] gebruik en gebruikers beslissen wanneer ze wel en niet opnemen. In de loop der jaren zijn apps zoals Strava geëvolueerd en volgen ze nu ook woon-werkverkeer als afzonderlijke categorie. Maar de aanvankelijke bias er nog steeds: de doelgroep wil dat.
We hebben daarom een manier nodig om crowd-sourced data, ondanks hun intrinsieke bias, in wetenschappelijk onderzoek te gebruiken. Aan de hand van het voorbeeld van een grote Strava-dataset van fietsgedrag in de Nederlandse Drechtstedenregio laten we zien hoe self-trackinggegevens effectief te gebruiken zijn om algemene fietspatronen te onderzoeken, in combinatie met Space Syntax als state-of-the-art modelleringsaanpak. Met als uiteindelijk doel om de investeringsbeslissingen van lokale en regionale overheden effectiever te maken.
Modelleren is noodzakelijk om meerdere datasets in een consistent raamwerk te combineren en uit die gecombineerde data de juiste en diepgravender conclusies te trekken.
METHODE
Drechtsteden is een verstedelijkt gebied met ruim 250.000 inwoners in Nederland. Dordrecht is de kernstad van deze regio, die zelf een subregio is binnen de wijdere agglomeratie Rotterdam. Door de enigszins zelfstandige ligging is de Drechtsteden goed geschikt voor fietsonderzoek.
We gebruiken fietsgegevens uit drie verschillende bronnen:
Ten eerste een Strava-dataset met 109.941 verplaatsingen met een herkomst en/of bestemming binnen de Drechtsteden, geregistreerd in een periode van één jaar [juli 2015-juni 2016] door 16.412 personen [88% mannen, 12% vrouwen]. De basistoepassing van de Strava-app is het vastleggen van fietstrainingsgedrag. Dit is onze belangrijkste dataset. Strava had in 2015 naar schatting 70.000 actieve Nederlandse gebruikers [Slavonië, 2015]. Strava-gegevens zijn crowdsourced maar niet vrij toegankelijk.
Ten tweede een kleinere dataset van de Fietstelweek met ongeveer 25.000 fietsritten met een herkomst en/of bestemming binnen de Drechtsteden, opgenomen in de week van 19-25 september 2016. De Fietstelweek is bedoeld om de ‘normale’ dagelijkse bewegingspatronen vast te leggen. Deze dataset is crowdsourced en wordt hier alleen gebruikt ter vergelijking met de Strava-set. Het deel van de set dat de fietsgegevens bevat is vrij toegankelijk voor niet-commercieel gebruik, inclusief wetenschappelijk onderzoek. [Lopen, openbaar vervoer en autogebruik zijn overigens ook geregistreerd. Deze data is niet toegankelijk.]
Ten derde tellingen verzorgd door de gemeente Dordrecht. Deze set is opgenomen in de week van 19-25 juni 2013. Het bevat gegevens over 23 stadslocaties. Het tellen gebeurde middels pneumatische ‘telslangen’ op het wegdek. Dit is zowel geografisch als numeriek een kleine set in vergelijking met Strava. Dit beperkt ernstig wat kan worden bereikt door alle sets te vergelijken. Op de 23 poorten zijn de geregistreerde passages wel veel hoger dan in de beide andere sets: 33.915, versus 1.922 voor Strava en slechts 436 voor Fietstelweek.
Alle gegevens zijn gevisualiseerd op basis van fietsinfrastructuur-gegevens van Openstreetmap.
Daarnaast hebben we een Space Syntax-model van de regio Drechtsteden gebouwd, en geanalyseerd met behulp van de open source software DepthmapX, ontwikkeld door de UCL Londen. We gebruiken dit model om de drie datasets in een zinvol en consistent kader te plaatsen. Op deze manier hopen we verborgen verbanden en/of specifieke gebruikersgroepen of gedragingen te identificeren en te verklaren.
Dat doen we in 3 stappen:
Stap 1: Vergelijk de drie datasets rechtstreeks, alleen op de 23 poorten. Deze verkennende analyse geeft een voorproefje van mogelijke correlaties.
Stap 2: Vergelijking van de drie datasets indirect, via het Space Syntax-model, alleen op de 23 poorten. Dit levert vermoedelijk wat extra inzichten op, maar is nog verkennend.
Stap 3: Focus op de relatie tussen de grote Strava-dataset en het Space Syntax-model. Omdat zowel data als model de hele regio beslaan, maakt dit breder en diepgaander onderzoek mogelijk dan in de vorige twee stappen.
Strava data: Beschrijving en visualisatie
De Strava-dataset verzamelt de gegevens van fietsers op drie verschillende niveaus: op knooppunten, op wegvakken en binnen polygonen van oorsprong-bestemming. Om de privacyredenen zijn alleen geagreggeerde routes beschikbaar, geen individuele routes.
Voor zowel wegvakken als knooppunten worden verkeersintensiteiten gerapporteerd. Voor randen ook de richtingen en verplaatsingstijden, voor knooppunten zijn de wachttijden inbegrepen. Daarom zijn de gegevens ook geschikt om specifieke tijdframes te analyseren, bijv. spitsuren.
Individuele ritten worden opgeslagen in een aparte herkomst-bestemmingsdataset [HB-data]. Voor elke reis wordt het herkomst- en bestemmingsgebied gegeven, plus alle tussenliggende gebieden die tijdens de reis zijn doorkruist. Een gebied is in ons geval het Nederlands laagste bestuursniveau, wat zich min of meer vertaalt naar een wijk. Wederom vanwege privacyoverwegingen worden in de HB-gegevens alleen vertrektijden vermeld, maar aankomsttijden niet. Dus noch de exacte vertrek- en aankomstlocatie, noch de exacte route van een individu kan uit deze dataset worden gereconstrueerd.
Met de Strava-app kunnen gebruikers elke rit labelen met een modus [‘lopen’, ‘hardlopen’, ‘fietsen’ enz.] en doel [‘training’, recreatief’, woon-werkverkeer’ enz.]. Dit is verplicht. Bovendien beoordeelt een algoritme reizen als woon-werkverkeer of niet op basis van namen die gebruikers aan reizen hebben gegeven. Weer een andere softwaremethode beoordeelt reizen alleen als woon-werkverkeer als de herkomst en bestemming niet identiek zijn. Hoe deze drie methoden samenwerken is niet transparant. Strava markeerde 31% van alle reizen in een jaar in de Drechtsteden als woon-werkverkeer. Van deze reizen vonden we echter dat 4% nog steeds een identiek herkomst- en bestemmingsgebied had terwijl ze meer dan één gebied doorkruisten. Wij beoordelen deze rondreizen niet als woon-werkverkeer. We hebben deze reizen uit onze woon-werkanalyse verwijderd.
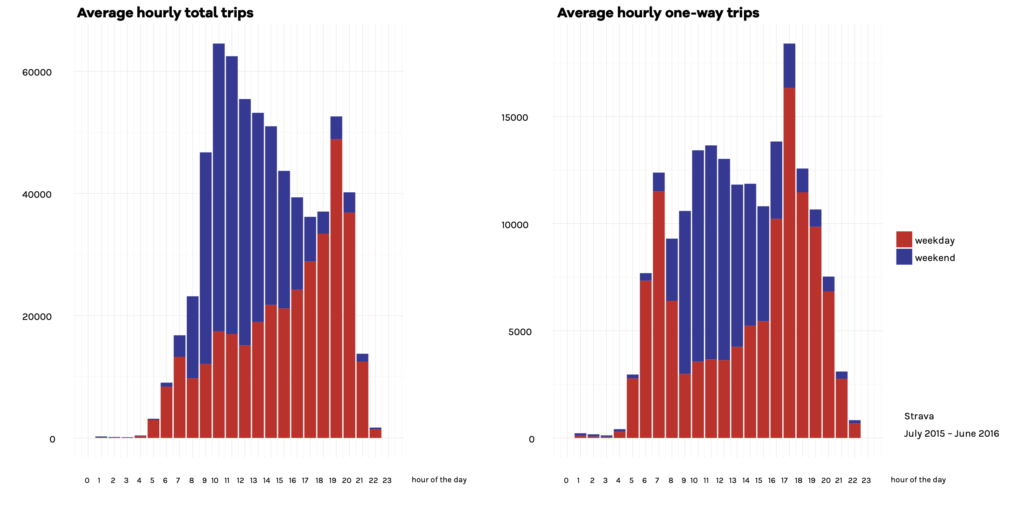
Na deze correcties waren de totalen voor woon-werkverkeer redelijk eenvoudig te visualiseren. We gebruikten hiervoor de kop/staart-methode [Bin Jiang, 2013]. Dit is een een manier om gegevens te classificeren met een verdeling zoals in zoals machtswetten en lognormale verdelingen. Precies zoals die zich manifesteren in fietsgegevens. De methode laat de onderliggende schaalverdeling van veel meer lage waarden dan hoge waarden [‘de 80/20-regel’] haarscherp zien. Conventionele classificatiemethoden, zoals vaak gebruikt in GIS, kunnen dit niet en zijn daarom minder geschikt om met verkeersdata om te gaan.
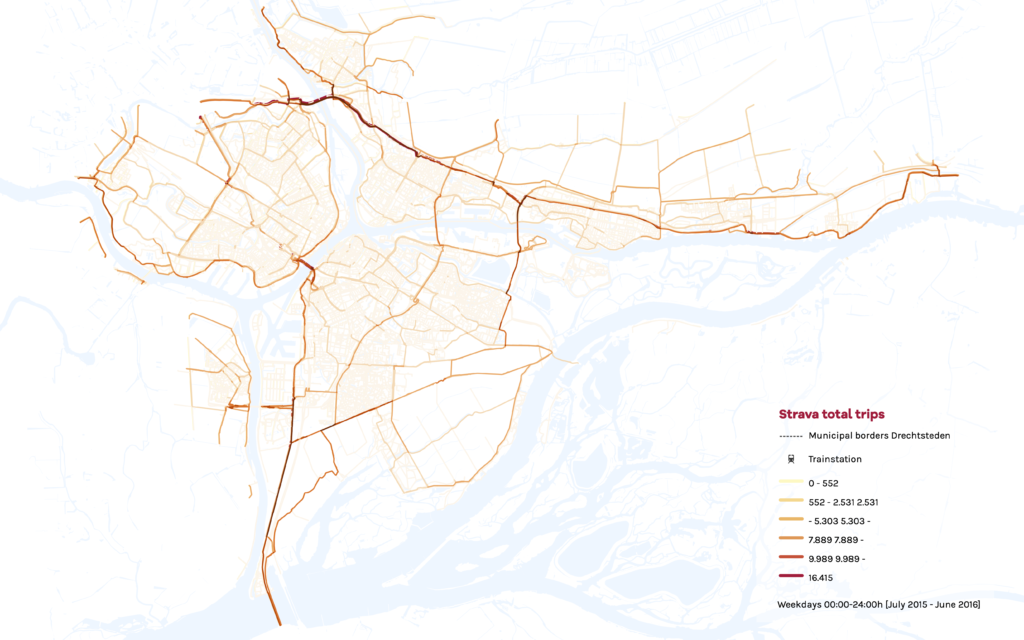
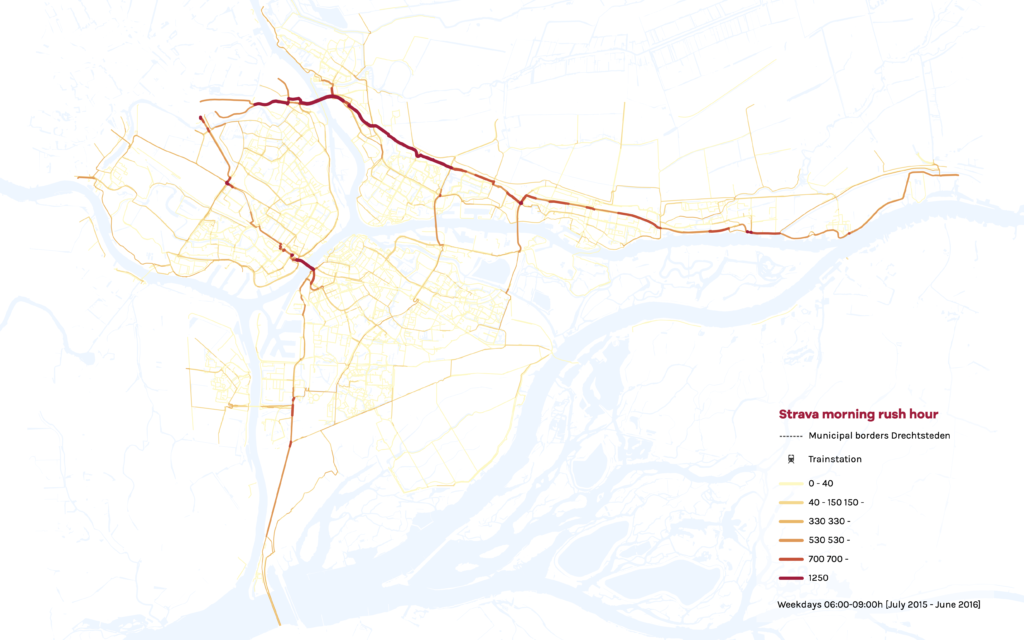
Om specifiek woon-werkverkeer te vangen, visualiseerden we zowel normale dagelijkse intensiteit [0.00-24.00 uur] als doordeweekse ochtendspits [08.0-09.00 uur] fietsintensiteiten. Het is duidelijk dat de spits een ‘extreme’ versie is van het normale dagelijkse patroon: Het fietsverkeer concentreer zich op slechts enkele hoofdroutes. Het dagpatroon toont minder nadruk op die hoofdroutes, meer gebruik van secundaire routes en meer fietsen in het omringende landschap.
Fietstelweek data: Beschrijving en visualisatie
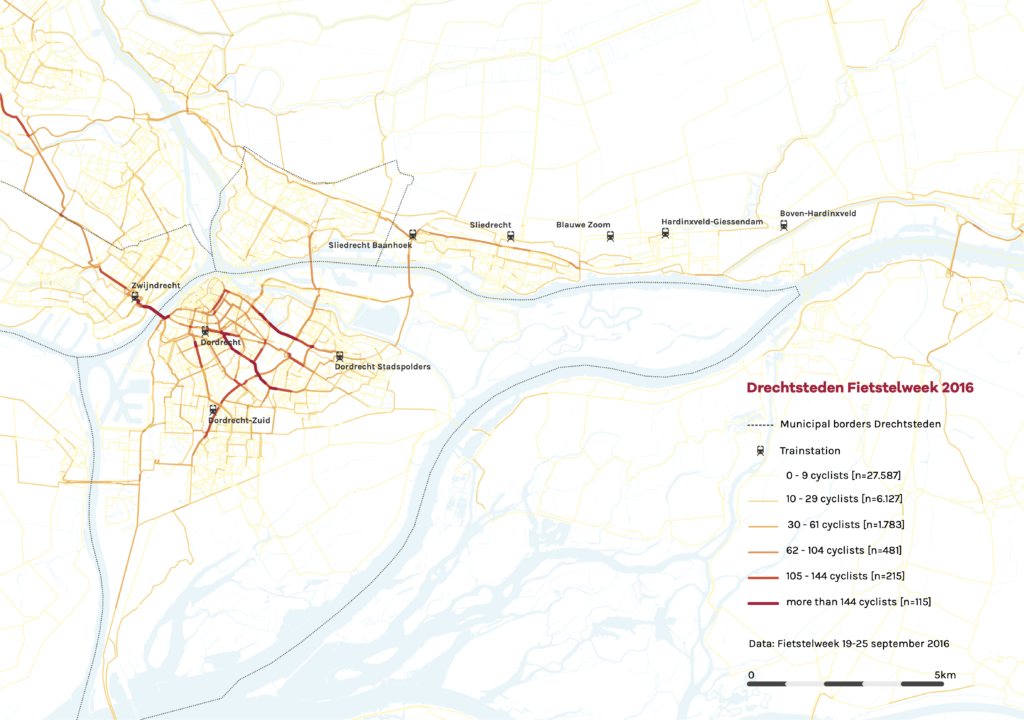
De gegevens van de Fietstelweek werden slechts één week per jaar verzameld. We gebruikten gegevens uit 2016. Dat wordt verzameld door middel van een speciale app, die deze week altijd aan staat. Een algoritme classificeert elke trip als fietsen of andere vervoerswijzen. Deze dataset is kleiner, maar toch enigszins vergelijkbaar met Strava: De Fietstelweek had in 2016 29.000 gebruikers voor heel Nederland, 1.800.000 km gefietst in totaal 400.000 ritten. Het gebruikersbestand is representatief voor de Nederlandse bevolking. De mannelijke oververtegenwoordiging van Strava ontbreekt volledig in de Fietstelweek.
De app maakt geen onderscheid tussen woon-werkverkeer of andere doeleinden: ritten blijven ongelabeld.
Zoals te zien is in figuur 5, verschillen de geaggregeerde fietspatronen van Fietstelweek-gebruikers sterk van die van Strava-gebruikers.
Space Syntax: Een netwerkanalyse-methode
Space Syntax is de combinatie van een conceptuele theorie, een onderzoeksmethode en een softwarepakket voor ruimtelijke analyse op de verschillende schalen van gebouw, straat, stad en regio. Hoe individuen bewegen en met elkaar omgaan, hangt nauw samen met de ruimtelijke vorm van en relaties binnen deze schaalnetwerken. Deze accommoderen en vormen de zogenaamde natuurlijke beweging. Space Syntax bestudeert fundamentele geometrische netwerkrelaties om de dynamische relaties tussen natuurlijke beweging en sociale en economische verschijnselen te begrijpen. Dit levert een samenhangend, bottom-up en robuust model van de gebouwde omgeving op. Space Syntax is gebruikt op uiteenlopende gebieden als sociologie, psychologie, archeologie, criminologie, transportplanning en economie.
Space Syntax wordt steeds vaker toegepast als onderlegger voor stedelijke ontwikkelingsplannen. De methode is tot op zekere hoogte in staat om de functionele gevolgen van voorgestelde projecten betrouwbaar te voorspellen. Dit heeft Space Syntax tot een nuttig en praktisch hulpmiddel gemaakt voor het informeren van investeringsbeslissingen van lokale overheden en vastgoedontwikkelaars.
Mogelijke correlaties tussen fietsersstromen en Space Syntax-modellen zijn eerder bestudeerd. Meerdere studies vonden correlaties [Raford 2005, Nordström 2015, Nourian 2015, Cooper 2016], zij het met gebruikmaking van onderling inconsistente variabelen, methodologieën en schalen/radii. We gebruikten beide variabelen waarvan werd vastgesteld dat ze het meest significant verband hielden met fietsgedrag: Angular Betweenness [BTNS] – meestal ‘Choice’ genoemd in de Space Syntax-literatuur – en Normalized Angular Betweenness [Normalised BTNS] – in die literatuur vaak aangeduid als NACH.
Betweenness is een maat voor hoe vaak een netwerkverbinding op een kortste pad ligt tussen alle paren knooppunten in [een deel van] het netwerk. ‘Kortste pad’ is daarbij geometrisch gedefinieerd als het pad met de minste totale hoekverandering.
Normalized Betweenness gebruikt dezelfde BTNS-waarden en deelt deze door de totale som van alle mogelijke kortste paden in het gegeven netwerk.
Hoewel we in eerder commercieel onderzoek meestal concludeerden dat zowel BTNS als genormaliseerd BTNS in een straal van ±2500 m goed correleerden met fietstellingen in een aantal Nederlandse steden, hebben we dit onderzoek niet beperkt tot een vooraf gedefinieerde straal.
RESULTATEN
Verkennende analyse van de drie datasets
Step 1: Combineer alle fietsdata op de 23 locaties in de GateCounts dataset.
Uit directe vergelijking blijkt dat Fietstelweek en GateCounts onderling goed corelleren [R2=0,58] op de 23 waarnemingspunten, maar Strava duidelijk afwijkend is. Noch met Fietstelweek [R2=0,03-], noch met GateCounts [R2=0,00] lijkt er relatie.
Ook in de hierboven gepresenteerde kaarten zijn de verschillen tussen Strava en Fietstelweek opvallend. Wat betekent dat? Is één van de sets, met name Strava, ‘fout’? Tonen ze verschillende gebruikersgroepen of verschillende gebruiksscenario’s? En hoe te beslissen welke set [of combinatie van sets] het meest geschikt is om ruimtelijke invetseringsbeslissingen op te funderen? Stap 2 probeert daarop een antwoord te formuleren.
Step 2: Integreer de bovenstaande data in het Space Syntax-model.
Deze stap toont zowel correlaties als verschillen van alle drie de datasets met het model.
De Strava-gegevens tonen alleen een significante correlatie met het Ssx-model op regionale straal [Rn, in rood]. De gegevens van de Fietstelweek laten een goede correlatie zien met het Space Syntax-model voor een reeks tussenradii [R2500m tot R6000]. Op regionale schaal is het gebruik van de Fietstelweek te laag om correlaties significant te maken. De GateCounts-gegevens tonen een sterke correlatie met het Ssx-model voor lokale tot tussenliggende radius [R1500 tot R2500].
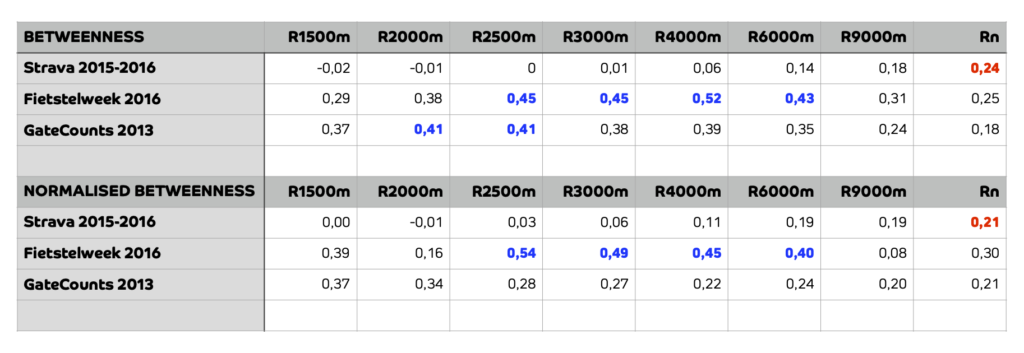
GateCounts zijn erg gevoelig voor het verwijderen van uitschieters. Het elimineren van 4 locaties versterkt de correlatie tussen data en model aanzienlijk [bijv. R2=0,64 bij BTNS R2000m]. De andere twee datasets hebben deze gevoeligheid niet omdat ze veel omvangrijker zijn.
Dit alles suggereert dat Strava wel degelijk zijn nut heeft, maar alleen op de grote schaal [Rn] van de hele regio Drechtsteden. De Fietstelweekdata registreert juist ‘dagelijkse fietsstromen’ op stadsschaal goed. De GateCounts werken op een nog kleinere straal, wat kan worden verklaard door de ligging van de telpunten in relatie tot de gefragmenteerde structuur van het Drechtstedengebied, met grote rivieren die het fietsen op grotere schaal belemmeren.
De over het algemeen zwakkere correlatie tussen Ssx-model en Strava-data was te verwachten, omdat Betweenness de kortste routes determineert. Over het algemeen is het gebruik van de kortste routes geen primaire overweging voor overwegend recreatieve fietsers.
Alle datasets bevatten duidelijke vooroordelen: Strava en Fietstelweek trekken verschillende subsets van fietsers aan die significant [Strava] of iets [Fietstelweek] bovengemiddelde activiteitsniveaus vertonen. De traditionele manier van tellen is echter ook bevooroordeeld, in die zin dat onderzoekers in hun ogen ‘relevante’ telpunten identificeren voordat ze daadwerkelijk gaan tellen. Zoals de andere sets laten zien, werden veel van de meest intensief gebruikte straatsegmenten door de gemeente gemist bij het bepalen van telpunten. Het gebruik van de crowdsourced-gegevens bij die keuze had kunnen helpen. Ook het Space Syntax-model had kunnen helpen bij het kiezen van telpunten die een beter algemeen, onbevooroordeeld beeld geven van fietsstromen in de hele regio Drechtsteden.
Step 3: Space syntax versus Strava: In-depth analyse
De derde en laatste stap in ons onderzoek is een diepgaande analyse van de correlatie tussen Strava-gegevens en het Space Syntax-model. We hebben de volledige Strava-dataset op alle wegsegmenten gekoppeld aan alle corresponderende Space Syntax-waarden in de hele Drechtsteden. Het gebruikte Ssx-model is gebaseerd op vereenvoudigde middenlijnen van wegen [n= 19.918]; de Strava-gegevens op Openstreetmap.
De voornaamste uitdaging van deze taak was om waarden te vergelijken op twee nogal verschillende netwerken: Openstreetmap, gebruikt door Strava, en ons eigen Space Syntax-model. We gebruikten een hexagonaal raster om de totale Strava-waarden over te dragen naar het Space Syntax-netwerk. Na het testen hebben we een celdiameter van 12 meter gebruikt, wat zowel voldoende nauwkeurigheid als genoeg rekenefficiëntie biedt.
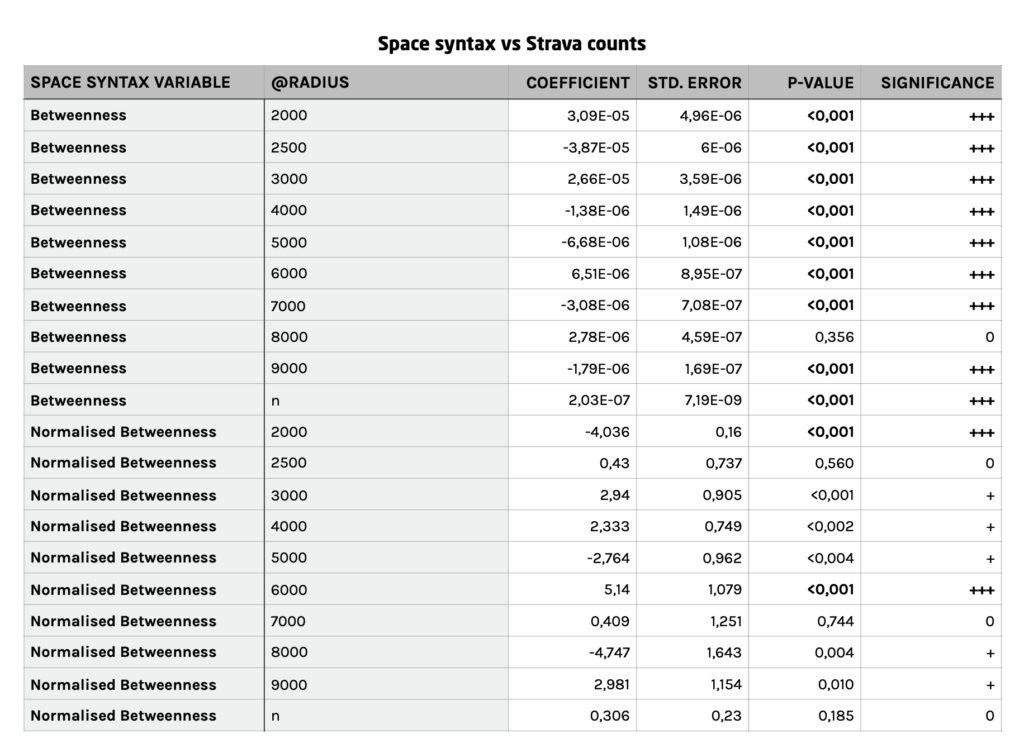
Het vergelijken van Space Syntax-waarden met de Strava-set vond significante correlaties, met name met de niet-genormaliseerde Betweenness-waarden. Zoals verwacht op regionale schaal, maar ook correlaties op meer lokale schalen. Dit suggereert dat Strava-gebruikers gevarieerde gedrag vertonen dan alleen ‘racen’. Ver en snel fietsen is zeker oververtegenwoordigd, maar de bruikbaarheid van Strava-gegevens voor algemene fietsinzichten is er wel degelijk. Zeker als andere gegevens ontbreken.
Toekomstig onderzoek zal zich richten op de mogelijkheid van nog verborgen, sterkere correlaties. Dit zou twee verfijningen vereisen: alleen Strava-ritten selecteren met de pendel-tag aan de gegevenskant, en de Space Syntax-analyse uitvoeren direct op het ongeoptimaliseerde Openstreetmap-netwerk. Binnen het kader van dit onderzoek was het niet haalbaar om twee verschillende manieren te modelleren.
DISCUSSIE
We hebben laten zien hoe Strava-gegevens bruikbaar zijn om fietspatronen weer te geven. We hebben ook aangetoond dat de gegevens van de Fietstelweek dezelfde capaciteit hebben, zelfs met sterkere correlaties op lage tot middelgrote schalen. Deze big data-sets lieten geen significante onderlinge correlatie zien in hun tellingen op 23 vooraf gedefinieerde poorten. De Fietstelweek had alleen een sterke correlatie met de GateCounts.
Alle drie de sets correleren echter significant met een Space Syntax-model van de Drechtsteden, zij het op deels verschillende radii. Het gebruik van Space Syntax bevestigt dat elke dataset een andere gebruikersgroep [of op zijn minst ander fietsgedrag] vastlegt, iets dat niet duidelijk was in de gegevens zelf. Bovendien biedt Space Syntax een solide basis voor het interpreteren van de gegevens, bv. het beoordelen of het aantal fietsers op een bepaald weggedeelte hoger of lager is dan verwacht.
Een modelleringsbenadering zoals Space Syntax kan verborgen eigenschappen binnen en relaties tussen datasets onthullen, die anders over het hoofd zouden zijn gezien. Het combineren van een theoretisch model en big data zorgt voor een eigentijdse werkmethode die behulpzaam is bij het begrijpen van en investeren in onze hedendaagse, complexe netwerksteden. Dit diepere begrip van de randvoorwaarden en gevolgen van stedelijke projecten maakt een zorgvuldigere besluitvorming mogelijk.
Problemen bij het werken met commerciële big data
Het werken met een grote, geografische, crowdsourced dataset, verkregen via een commerciële provider, bleek een aantal problemen te hebben die we niet niet allemaal voorzagen. Afsluitend daarvan een korte opsomming.
Probleem #01: Data-verwerving
Op dit moment is het verwerven van een dataset geen eenvoudig proces. Er is een groeiend aantal providers, allemaal met hun eigen bijzonderheden en die allemaal opereren onder de lokale privacywetten. Door deze beperkingen krijg je nooit toegang tot de onbewerkte gegevens, maar alleen tot een deelverzameling die al dan niet past bij je onderzoeksdoelen. Ten tweede kan aan acquisitie in totaal een flink prijskaartje zijn verbonden. Maar de prijzen per individuele trip zijn eigenlijk heel concurrerend in vergelijking met het vastleggen van reizen binnen een gecontroleerd wetenschappelijk experiment.
Probleem #02: Data corruptie
Verschillende soorten gegevenscorruptie komen regelmatig voor en zijn moeilijk op te sporen.
Geografische corruptie: Een totale fietstrip wordt soms in meerdere delen gesplitst, vanwege signaalonderbrekingen of -schaduwen door gebouwen enz. Providers proberen dit geautomatiseerd te herstellen en tripdelen opnieuw te koppelen. Dit is nooit helemaal succesvol.
Apparaatcorruptie: Fietsers gebruiken meerdere diensten en koppelen deze aan hun eigen fysieke volgapparatuur. Dit leidt tot compatibiliteitsproblemen, zoals dubbeltellen.
Tijdscorruptie: Na verloop van tijd zullen individuele gebruikers op een bepaald moment hun servicelidmaatschap beëindigen. Privacywetten vereisen dat hun gegevens door de service worden verwijderd. Dus elke crowdsourced-dataset is niet alleen beperkt tot het tijdsbestek waarin de gegevens zijn geproduceerd, maar ook door de datum waarop deze zijn opgehaald.
Moduscorruptie: Trackingsoftware en -services gebruiken algoritmen om reismodi te labelen. Snelheid wordt gebruikt als een van de determinanten. Dit proces van labelen heeft een behoorlijke foutmarge. Tijdens de spits kunnen fietsers binnenstedelijk zelfs sneller rijden dan automobilisten, wat dus leidt tot verkeerd gelabelde reismodi.
Probleem #03: Data commercialisatie
Onlangs zijn veel populaire trackingdiensten overgenomen door multinationale bedrijven [Goode 2016]. RunKeeper is gekocht door hardloopschoenenmaker Asics. Endomondo, MyFitnessPal en MapMyFitness gingen naar Under Armour. Runtastic werd overgenomen door Adidas [Goode 2016]. Dit vormt een groeiend risico voor de toegang van het publiek tot crowdsourced data. Inmiddels zijn enkel van deze services opgeheven, met verlies van data.
Er zijn ook groeiende privacykwesties. Zowel RunKeeper als MyFitnessPal houden continu gebruikerslocaties bij, zelfs als de app niet actief is. RunKeeper levert deze gegevens aan een marketingbureau [Pultier 2016]. Android staat apps toe om dit te doen. Dit zal op dit moment misschien niet direct van invloed zijn op wetenschappelijk onderzoek, maar het roept zeker ethische vragen op over welke bron wél te gebruiken en welke niet.
Probleem #04: Menselijke data bias
Crowdsourced datasets worden verzameld door een specifieke gebruikersgroep en/of voor een welomschreven doel. Er is dus sprake van een vooroordeel. Omgaan met deze vooringenomenheid in wetenschappelijk onderzoek betekent het op de een of andere manier opschonen van de dataset, de vooringenomenheid te neutraliseren door datasets uit andere bronnen toe te voegen [zoals in dit onderzoek] of de vooringenomenheid bewust te gebruiken, omdat dat nuttig is bij het beantwoorden van een specifiek onderzoeksdoel. De inherente voorliefde van Strava voor recreatief fietsen is misschien niet handig bij het vinden van dagelijkse stedelijke gebruikspatronen, maar kan helpen bij het identificeren van mogelijke investeringen in fietsinfrastructuur: Recreatief fietsen is verreweg de snelst groeiende categorie fietsen in Nederland.
Minder zichtbaar, maar mogelijk net zo belangrijk, is de opgebouwde persoonlijke bias in de data. Mensen die hun gegevens aan webgebaseerde services geven, bouwen, bewust of onbewust, een geïdealiseerd digitaal zelfbeeld op. Ze zelfcensureren hun eigen activiteiten. In het geval van Strava resulteert dit mogelijk in een kunstmatige boost voor snel en ver fietsen in de publieke digitale representatie van de private fysieke realiteit.
Probleem #05: ‘Harde’ data versus ‘zachte’ data
Sommige soorten data zijn gemakkelijker te verzamelen dan andere. ‘Harde’ data over bijv. reiskosten, reistijd, reisintensiteiten en herkomsten-bestemmingen zijn, via [commerciële] derde partijen, redelijk toegankelijk. Maar ‘zachtere’ factoren, zoals comfort, aantrekkelijkheid, de perceptie van betrouwbaarheid en sociale interacties blijven mistig. Strava-gebruikers fietsen vaak in groepen, die heel andere routevoorkeuren kunnen hebben dan individuen. Kortom: Vervoerspatronen vallen niet te verklaren op basis van alleen harde gegevens over individuele reizigers.
Probleem #06: Data pre-processing
Gegevens worden eerst geproduceerd en geüpload door gebruikers en uiteindelijk gedownload en geanalyseerd door onderzoekers. Maar daartussen gebeurt er ook van alles: Gegevens worden bewerkt, gelabeld en gewijzigd. Dit gebeurt in toenemende mate door zelflerende algoritmen en neurale netwerken. Deze toenemende afhankelijkheid van kunstmatige intelligentie maakt het voor de mens steeds minder inzichtelijk hoe gegevens worden geproduceerd en verwerkt. De nogal vaag gedefinieerde ‘woon-werkverkeer’-tag in de Strava-dataset – een combinatie van drie verschillende mechanismen waarvan er één op de gebruiker is gericht en twee op software zijn gebaseerd – is slechts een klein voorteken van grotere dingen die komen gaan.
Probleem #07: Data diepte
Is big data wel écht ‘big’? Vrij beschikbare crowdsourced datasets kunnen miljoenen records bevatten. Dat lijkt een ‘gegevensdiepte’ die binnen een individueel onderzoeksproject niet op een andere manier te bereiken is. Maar zoals we hebben gezien, moet een significant aandeel van zo’n dataset als irrelevant of onvoldoende betrouwbaar afgedaan worden. En, zoals we ook hebben gezien, kunnen met één week consequent tellen op een telpunt veel hogere aantallen worden bereikt dan in de beschikbare big data sets voorhanden is. Dus zelf tellen houdt de voorkeur, als de onderzoeksvraag geografisch of qua gebruiksgroep beperkt van omvang is. De vertrouwde telslang blijft bovendien een betrouwbare manier om een omvangrijkere big dataset te controleren en valideren.
Probleem #08: Onjuist data-gebruik door de overheid
Door sommigen wordt de ‘Data Driven Society’ aangeprezen als dé weg voorwaarts naar een duurzame toekomst. Voor een lokale politicus is het zowel aantrekkelijk als risicoloos om te investeren in fietspaden waarvan uit big data blijkt dat ze al het drukst gebruikt worden. Maar de toekomst van onze steden is niet gediend met zulke simplistische redeneringen. De Fietstelweek en Strava kaarten zijn handig om te laten zien waar op dit moment intensief wordt gefietst. Maar betekent dat dat steden moeten stoppen met investeren in minder gebruikte routes? Misschien is juist dáár investeren nodig. Daarom: Data alleen mag nooit 1-op-1 leiden tot besluitvorming. De ‘datagedreven samenleving’ is geen ideaal: een breder perspectief is altijd nodig.